


ChatGPT 열풍. 거대 AI는 과연 세상을 바꿀 기술일까요?
ChatGPT로 시장이 뜨겁습니다. 모두가 인공지능을 이야기하고 있는 지금 우리는 어떤 투자 기회를 만날 수 있을까요? 투자자로서 냉정과 열정 사이 그 어딘가를 찾아봅시다.

ChatGPT 출시로 시장의 기대가 뜨겁습니다. 그동안 돈 먹는 하마였던 거대 인공지능 모델이 드디어 뭔가 쓸만해 보이는 서비스를 내놓은 것처럼 보입니다.
투자자들 역시 ChatGPT가 바꿔놓을 세상에 대해 많은 기대를 하고 있는 것 같습니다. ChatGPT가 출시된 22년 11월 30일 이후, 인공지능이라는 키워드를 사업 내용에 포함하고 있는 회사들은 현재까지도 연일 좋은 주가 흐름을 이어가고 있습니다.


이번에 가격이 오른 회사들은 모두 ChatGPT와는 별 상관이 없어보이는데요?
사실 저도 ChatGPT의 테마로 주가가 상승하고 있는 회사들에 예상되는 실질적인 사업 수혜가 있냐라는 질문에는 '아니다'라고 대답할 것 같습니다. 실제로 뉴스를 찾아봤지만 특별히 ChatGPT와 연관된 사업을 하거나 계획을 발표한 회사는 없었습니다.
이번 상승은 직접 인공지능 모델을 개발하는 회사에 그치지 않고 후방 산업의 많은 종목들까지도 영향을 미치기 시작했습니다. AI 반도체 같이 향후 수요 상승이 가시적으로 점쳐지는 회사부터, 조금 의아하긴 하지만 PCB 회로기판를 만드는 회사에 이르기까지 다양한 종목들이 ChatGPT 수혜주로 주목을 받고 있습니다.
전반적인 인공지능 산업에 대한 Rerating이 이뤄지고 있는 시점인 것 같습니다. 많은 시장 참여자들이 인공지능이라는 키워드에 주목하는 것은 고무적인 일이나, 우리는 또 한번의 단기적인 Hype 앞에 서있는지도 모릅니다.
거대 인공지능
사람들은 언제고 ChatGPT와 같은 거대 인공지능에 대한 환상을 갖고 있었습니다. 인공지능과 대화하고 내가 원하는 일을 뚝딱 해줄 수 있는 디지털 비서에 대한 열망은 거대 인공지능이 Sci-fi를 넘어 실질적인 산업에까지 뿌리 내리게 한 원동력이기도 합니다.
하지만 투자자로서 우리는 환상과 현실 사이 적절한 어딘가에서 중심 찾아야 합니다. 오늘은 거대 인공지능이 가져다줄 효과와 거품을 구분하기 위해 머릿속에 맴도는 생각들을 정리해보았습니다.
(본격적인 내용에 앞서) ChatGPT는 무엇인가?👇
OpenAI에서 개발한 자연어 생성 모델 GPT-3.5를 기반으로 개발된 인공지능 챗봇 서비스
GPT는 주어진 텍스트의 다음 단어를 예측하는 과제를 학습한 인공지능 모델. 학습을 거친 모델은 사람과 같이 자연스러운 Lanaguage Generation을 할 수 있게 됨
OpenAI는 "고급 AI가 모든 인류에게 혜택을 주도록 한다"는 미션을 가진 비영리 조직으로 출발하였으나, 영리 법인 OpenAI Inc.를 설립하며 사실상의 영업 활동을 하고 있음
거대 인공지능 모델의 함정 : 일반적인 말은 잘 알아듣는데...
이 산업을 오랫동안 지켜보신 분들이라면 Model-centric에서 Data-centric으로 변화하는 인공지능 모델의 개발 흐름에 대해 인지하고 계셨을 것입니다. 소프트웨어의 설계 자체보다는 학습하는 데이터의 양과 질이 모델 성능에 더 중요한 영향을 미친다는 것인데요.
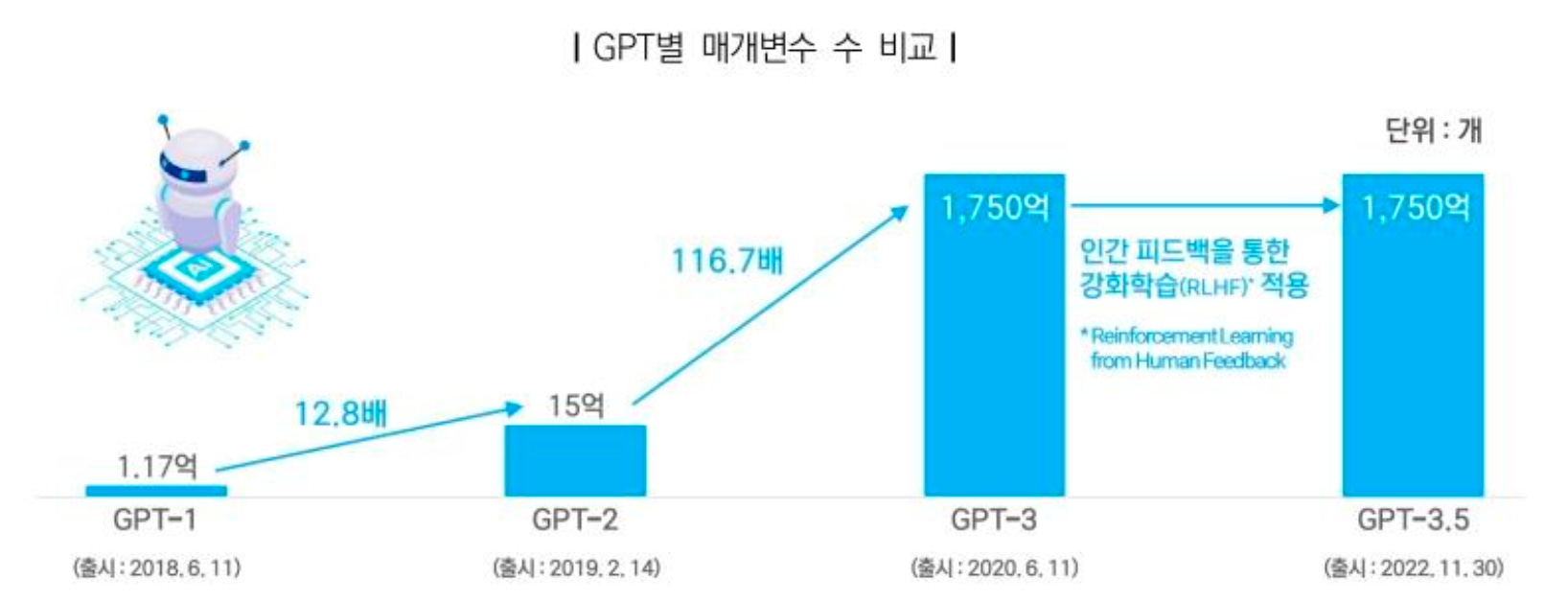
이번 ChatGPT에 사용된 GPT-3만 하더라도 이전 버전인 GPT-2에 비해 117배의 매개변수를 사용했고, GPT-1에 비하면 1,500배나 되는 매개변수를 사용했습니다 (학습에 사용된 매개변수의 수가 많을수록 데이터도 많이 필요하게 됩니다). 이렇듯 빅테크에서도 이전 버전보다 더 나은 성능을 내는 거대 인공지능 모델을 출시하려면 최소 10배는 더 많은 데이터를 학습해야 하는 게 일반적인 상식이 되고 있는 상황입니다.
하지만 이렇게 많은 데이터(라 쓰고 돈이라 읽는다)를 학습해 모델을 개발하고도, 정작 특정 서비스 영역에 사용하기엔 뾰족한 효용이 없다면 어떨까요?
실제로 투자 검토를 하다보면 스타트업, 또는 대기업의 팀 단위에서 전문 목적으로 개발된 인공지능 모델이 대기업의 거대 모델의 성능을 압도한다는 소식을 상당히 자주 들을 수 있습니다.
일례로 국내 인공지능 HR 서비스를 제공하는 무하유의 경우 자기소개 피칭 음성의 Speech-to-text 성능면에서 네이버의 한국어 음성인식 거대 인공지능 모델인 하이퍼클로바의 인식률을 뛰어넘는다고 하죠. 비교 되지 않을 정도의 많은 데이터를 학습한 인공지능일지라도 특정 영역에 특화된 학습을 한 모델 대비 전문 영역에서 효용성이 떨어지는 것은 어쩌면 당연한 결과로 보이기도 합니다.

거대 인공지능 모델을 특정 영역에 적용하는 게 꽤나 어려운 일임은 CES 행사장의 베가스 루프를 통해서도 알 수 있었습니다. 베가스 루프는 일론 머스크의 보링 컴퍼니가 만든 라스베가스 컨벤션센터의 지하 터널인데, 테슬라 차량으로 행사장 관람객들을 수송하는 역할을 합니다. 몇몇 후기 영상을 보면 개통 후 1년이 되는 지금 시점까지도 일부 구간에서 오토파일럿 작동하지 않아 사람이 전 구간을 직접 운전하고 있는 것을 볼 수 있습니다. 원인을 자세히는 알 수 없지만 테슬라의 거대 자율주행 모델로도 낯선 환경을 주행하는 일이 쉽지만은 않은 것 같습니다.

인공지능이라는 트렌드에서 투자를 할 때 잊지 말아야 할 것은 거대 인공지능 모델들 역시 특정한 Task를 수행하기 위해 개발된 한계가 분명한 소프트웨어라는 사실입니다.
거대 인공지능 모델은 내 종목과 어떤 시너지를?
여러분이 보유하고 있는 코스닥 회사 그리고 심사역으로서 투자한 스타트업들은 거대 인공지능 모델에 어떤 사업적 수혜를 받을 수 있을까요?
아쉽게도 GPT-3를 비롯한 거대 인공지능 모델들은 오픈소스로 공개되어 있지 않은 경우가 대부분입니다. 소스코드가 공개되어 있다 하더라도 Pre-trained 모델이 아니기 때문에 데이터를 수집, 가공, 학습하여 같은 성능을 내는데는 또다시 엄청난 비용이 듭니다.

OpenAI도 GPT-3를 오픈소스로 공개하지 않고 API 형태로만 제공하고 있습니다. 구글, 엔비디아, 메타 등 다른 빅테크의 인공지능 모델들 역시 오픈소스가 아니거나 제한적인 수준에서만 공개되어 있는 상황입니다. 앞으로도 이러한 인공지능 모델들의 자산화 추세는 계속될 것으로 보이며, 자사 제품에만 적용되거나 API, Framework 형태로 제공될 가능성이 높아 보입니다.
결국 대부분의 회사들은 제품화된 인공지능 모듈을 구매하여 사용해야 할 것으로 보이는데요. 소스코드를 내 비즈니스에 맞게 수정하고 다시 학습시켜 자체 모델을 만들 수 있지 않다면, 앞으로 거대 인공지능 모델을 활용해 어떤 사업 기회를 만들 수 있을지 저는 아직은 잘 모르겠습니다.
몇 가지 아이디어
리버스 엔지니어링한 오픈소스를 기반으로 자체 모델 개발
인공지능 모델의 API를 Wrapping 하여 사람들이 거대 인공지능 모델을 사용하기 쉽도록 만들어주는 서비스
Generative AI의 경우 사용자의 Input Prompt를 효과적으로 작성할 수 있도록 모듈, 서비스화
인터랙티브 서비스 (교육, 게임, 고객 응대 등)
실제 활용 Case
(미국) C3.ai가 GPT-3 활용하여 기업용 Search 엔진 출시
(한국) 베스핀글로벌이 자사 챗봇 HelpNow AI에 GPT 도입
그 외 각종 프로토타입 형태의 시도들 (GPT-3 활용 케이스 모음)
Use case에 대한 전망 (관련 기사)
아직 거대 인공지능 모델을 활용해 유의미한 사업적 성과를 만들어낸 플레이어가 많지는 않아 보입니다. 시장의 기대가 큰만큼 Hype과 Reality를 구분하려는 노력이 필요한 것 같습니다.
범용 AI는 언제 나오나
앞선 설명으로 ChatGPT의 GPT-3를 비롯한 거대 인공지능 모델들의 태생적, 비즈니스적 한계를 인식하게 되셨을 것이라 생각합니다. 이것들이 우리가 기대하는 자유자재로 소통하고 원하는 명령을 내릴 수 있는 범용 AI와는 많이 다르다는 것은 너무나 분명해보입니다.
그렇지만 공학자들은 때론 시장의 기대치를 뛰어넘는 놀라운 혁신을 만들곤 합니다. 실제로 일론 머스크는 지난 AI Day에서 인공지능을 탑재한 사람 형태의 로봇인 OPTIMUS 출시를 예고했고, 테슬라 내부에서도 실제로 무언가가 진행되고 있는듯 보입니다.

범용 AI를 탑재한 휴머노이드 로봇은 산업 그리고 시장 참여자들의 공통적인 꿈입니다. 우리는 지금 어디에 있고, 향후 3-4년 뒤에는 어디까지 도달할 것이며, 그 과정에서 어떤 투자 기회들이 발생할지 빠른 시일 내에 생각을 공유해보도록 하겠습니다.
인공지능 투자도 결국 Product-market-fit 입니다
오늘은 ChatGPT를 필두로 한 거대 인공지능 모델이 산업과 시장에 어떤 파급력을 가져올지에 대해 생각해보았습니다.
개인적으로는 Data-centric 인공지능 모델 트렌드가 전개됨에 따라 빅테크와 그 외 인공지능 회사들의 Market Positioning 차이는 더 뚜렷해지고 있다고 생각되는데요. 거대한 자본력을 바탕으로 강력한 확장성을 가진 플랫폼을 개발하는 빅테크와 Product-market-fit으로 뾰족한 날을 세워 대응해야 하는 중소 벤처 스타트업의 구도는 비단 어제 오늘의 이야기는 아닌 것 같습니다.
인공지능 회사들을 투자 검토하다보면 가장 많이 듣는 질문이 있습니다.
그래서 결국 SI 업체 아니야?
제품 개발, 데이터 확보를 위한 SI성 프로젝트의 수주는 초기 인공지능 업체에겐 숙명과도 같은 일이라 생각합니다. 다만 투자자로서 이 같은 질문에 No 라고 얘기할 수 있었을 때는 모두 전방 시장의 실제 수요가 있고, 충분히 Sizable하며, 회사 제품이 차별적인 Product-market-fit을 만들고 있다는 확신이 있는 경우였던 것 같습니다.
개인적으로 이런 회사에 관심이 많습니다
한국 산업 구조 상 많은 기회가 있을 것 같은 제조업 특화 AI 회사
산업용 로봇과 관련한 AI 회사
인공지능 개발의 작은 과정에서나마 확실한 메리트를 줄 수 있는 MLOps 회사
관련한 회사, 또는 제가 생각하지 못한 영역에서 차별적인 역량을 만들고 계신 대표님들의 연락을 항상 기다립니다. 어려운 시장 상황 속 ChatGPT 덕에 또 한번 주목 받고 있는 인공지능 회사들의 선전을 기원합니다.